In this project we examined how recommender systems work (better or worse) if we take advantage of the review texts along with the review ratings. We aimed to combine latent ratings with latent review topics and analyze the results. Our assumption was that combining the review text with ratings would help the recommender system make better predictions. Hence, we compared different models on Amazon Apps dataset and calculated RMSE.
Background
Recommender Systems mainly rely on human feedback in the form of ratings and reviews. Hence, the system suffers through the problem of cold start where new user or item does not have much of the feedback available. This makes the initial feedback a lot invaluable. Intuitively, one review gives a lot more information about the user compared to one rating.
In spite of the wealth of research on modeling ratings, the other form of feedback present on review websites—namely, the reviews themselves—is typically ignored. In our opinion, ignoring this rich source of information is a major shortcoming of existing work on recommender systems. Indeed, if our goal is to understand (rather than merely predict) how users rate products, we ought to rely on reviews, whose very purpose is for users to explain why they rated a product the way they did.[1]
Dataset
Amazon Apps
We used the “Apps for Android” 5-core Dataset which contains both product ratings and reviews. The dataset contains 752,937 entries with 87,271 users and 13,209 products (mobile apps). The data is from Amazon.com and has been collected by Julian McAuley, UCSD. Below is the snippet of the data:
{
"reviewerID": "A1N4O8VOJZTDVB",
"asin": "B004A9SDD8",
"reviewerName": "Annette Yancey",
"helpful": [1, 1],
"reviewText": "Loves the song, so he really couldn't wait to play this. A little less interesting for him so he doesn't play long, but he is almost 3 and likes to play the older games, but really cute for a younger child.",
"overall": 3.0,
"summary": "Really cute",
"unixReviewTime": 1383350400,
"reviewTime": "11 2, 2013"
}
{
"reviewerID": "A2HQWU6HUKIEC7",
"asin": "B004A9SDD8",
"reviewerName": "Audiobook lover \"Kathy\"",
"helpful": [0, 0],
"reviewText": "Oh, how my little grandson loves this app. He's always asking for \"Monkey.\" Grandma has tired of it long before he has. Finding the items on each page that he can touch and activate is endlessly entertaining for him, at least for now. Well worth the $.99.", "overall": 5.0, "summary": "2-year-old loves it",
"unixReviewTime": 1323043200,
"reviewTime": "12 5, 2011"
}Analysis
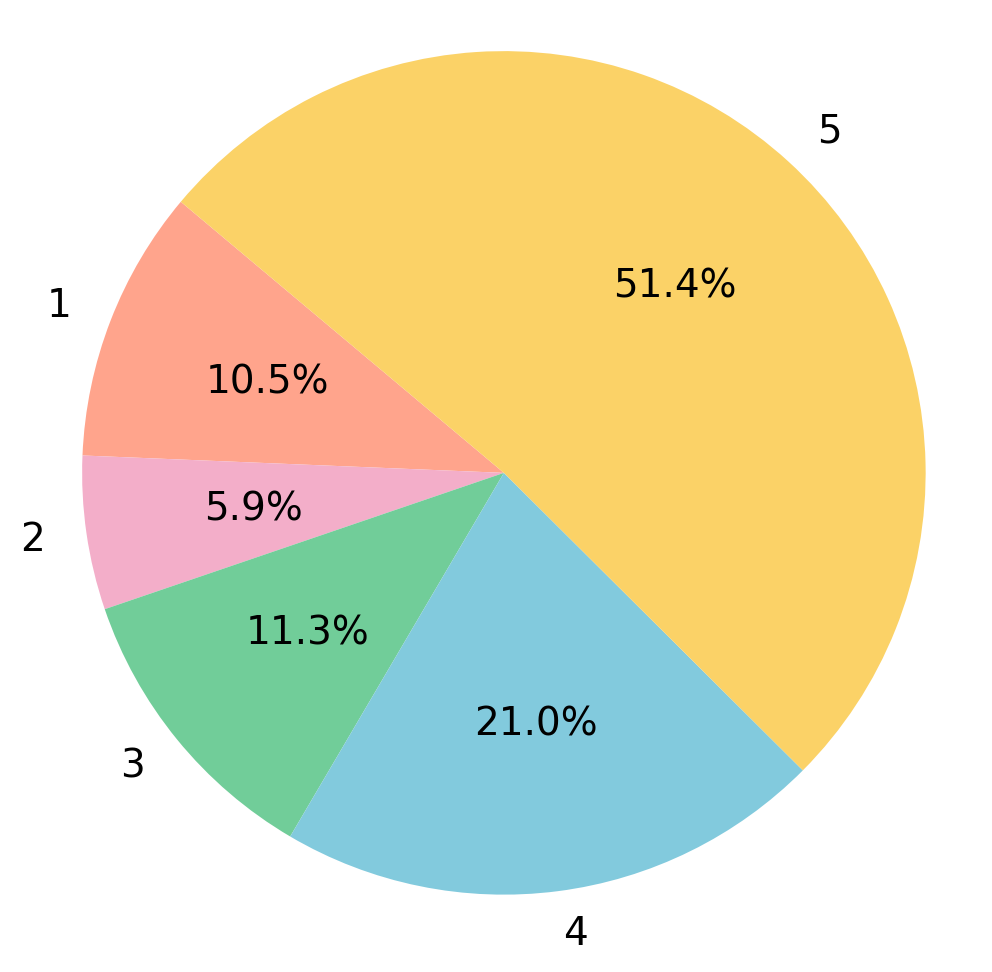
- About half of the items have ratings of 5.
- Average rating is 3.96.
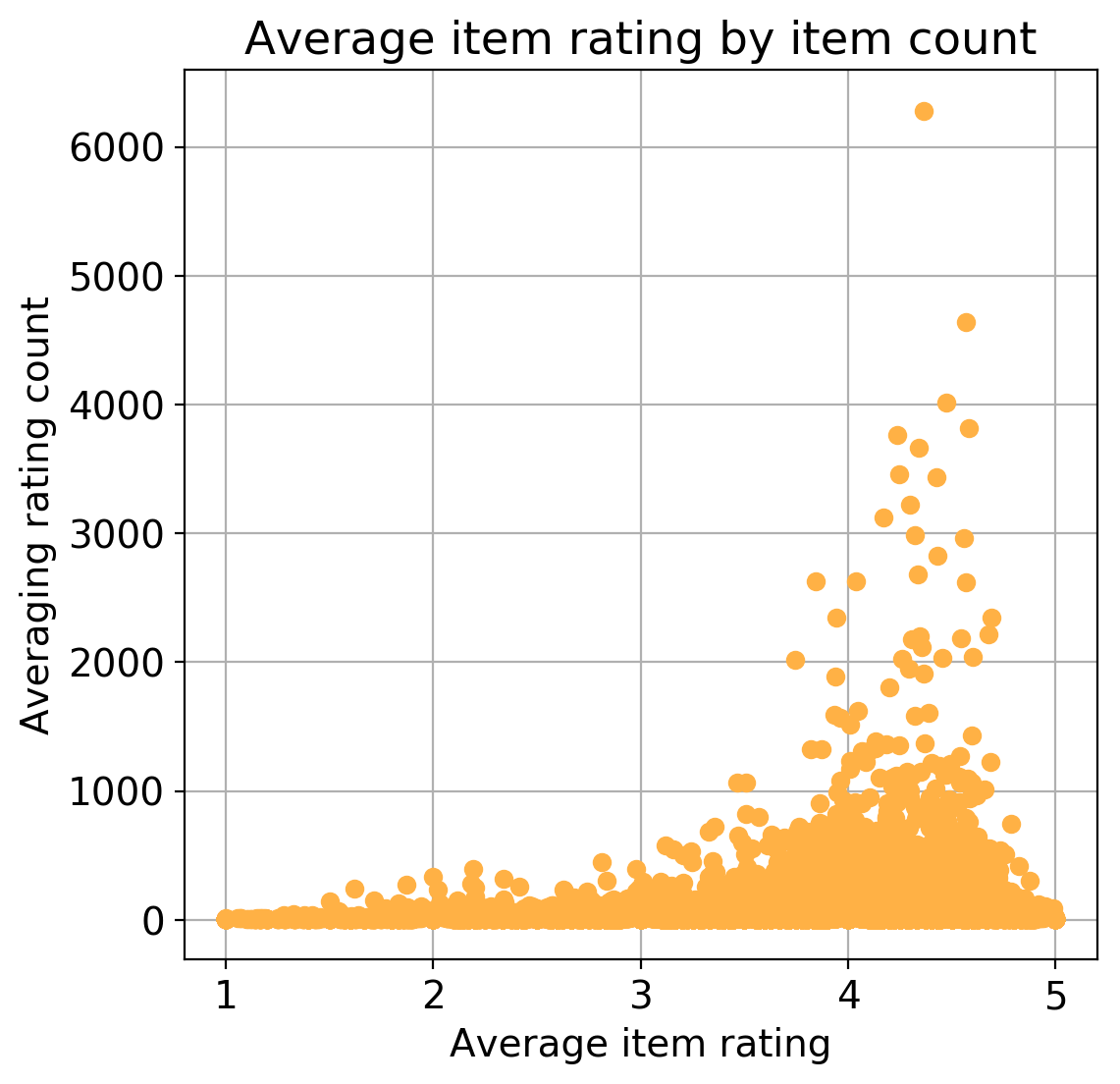
- On average, an item has 57 ratings.
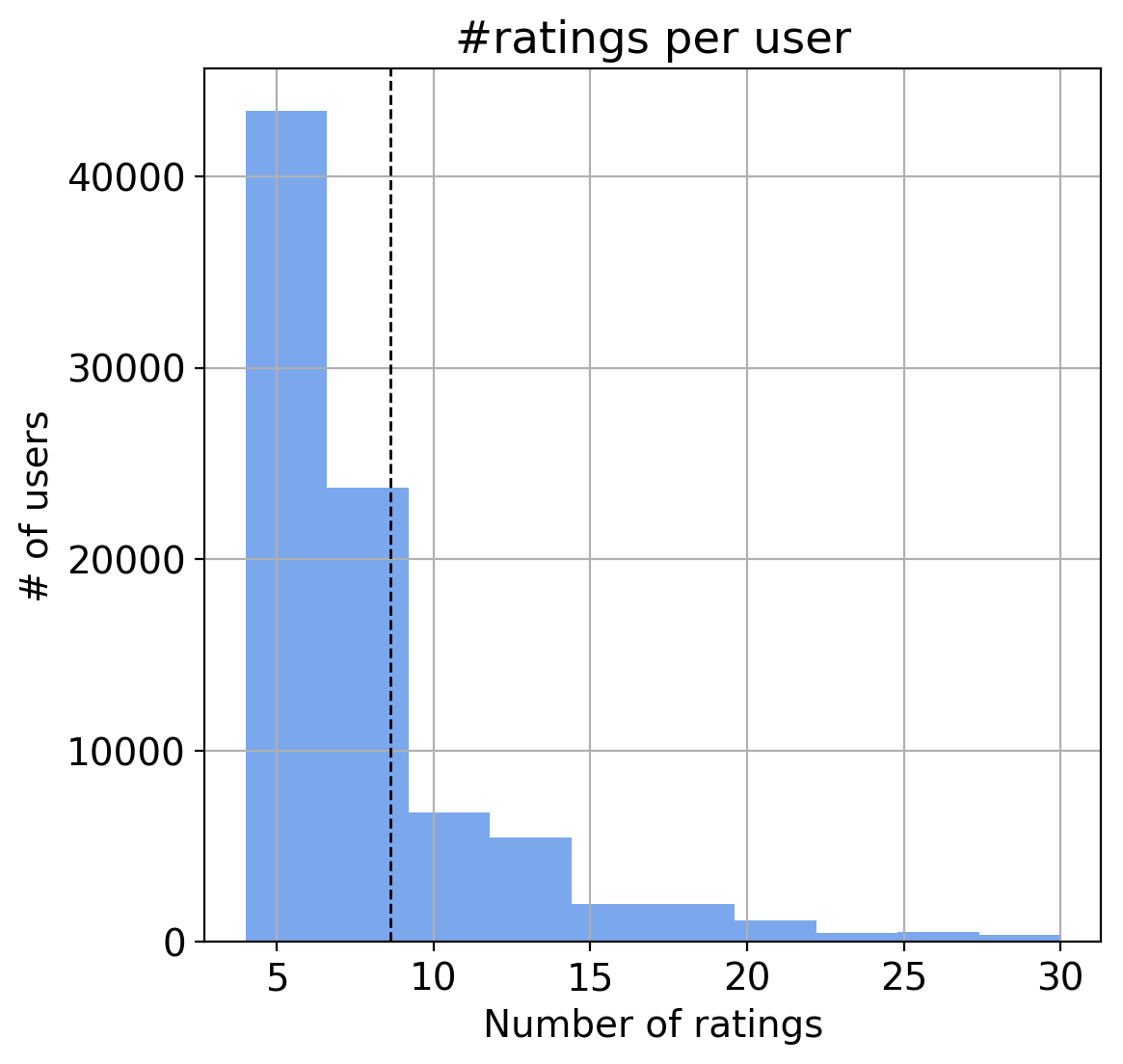
- On an average, a user rates about 9 items.
 |
 |
 |
|
Methodology
Preprocessing
- The dataset has the special property that each product has at least 5 reviews/ratings and each user has given at least 5 reviews/ratings.
- For splitting between training and testing data, we moved at least 1 review per user and at least 1 review per product to the test dataset and remaining to the train dataset.
Experimentation
We Compared and evaluated the following recommendation models:
- Global Average Model
- Baseline Model
- Collaborative Filtering
- Latent Dirichlet Allocation (LDA)
- Hidden Factors as Topics (HFT)
Global Average Model
We started with this approach to see what results we get if we use a model as straightforward as this one. In this, we predict the global average as the rating for each user-item pair.
Formula:

Baseline Model
This model is an improvement over the first one. In addition to the global average, we also consider a user bias and a movie bias while prediction.

Collaborative Filtering
In this approach we considered user-user collaborative filtering. We have used Pearson correlation to calculate similarity between two users. Also, we use 10 nearest neighbor approach for predicting the rating and for the recommendations.

Latent Dirichlet Allocation (LDA)
Every word in a review texts belongs to one or more topics. Using LDA, we can only observe the text and words, not the topic themselves. We tried to find these hidden topics in the text reviews and below is the distribution of these topics.
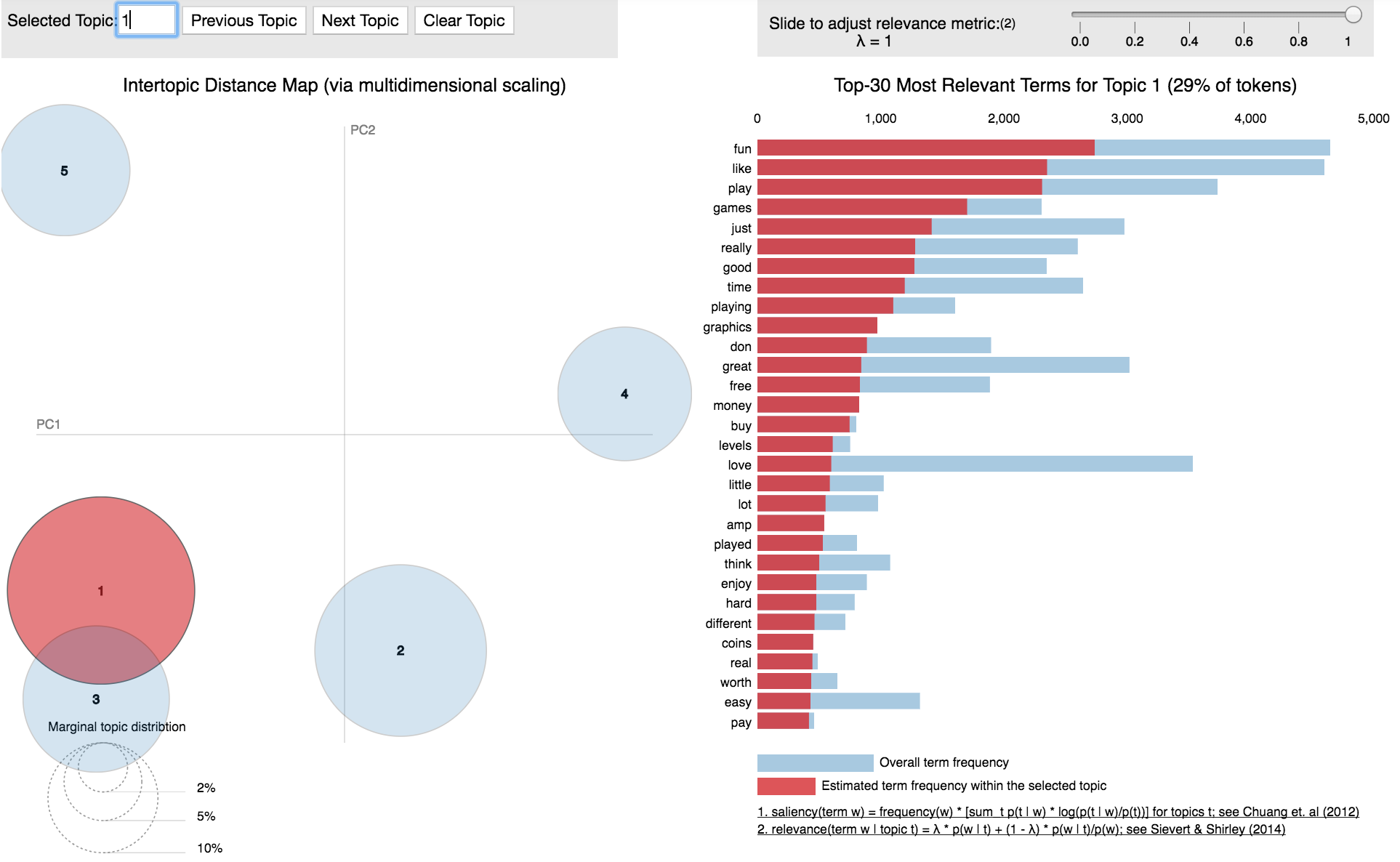 Once we get the word distribution per topic, for each document we calculate the topic distributions. Here, all the reviews on one product are considered as one document. Similarly, all the reviews given by one user are considered as one document.
Once we get the word distribution per topic, for each document we calculate the topic distributions. Here, all the reviews on one product are considered as one document. Similarly, all the reviews given by one user are considered as one document.

Hidden Factors as Topics (HFT)
HFT model takes advantage of both ratings and reviews by combining latent factor model and latent dirichlet allocation model. Here, for each user and item, we calculate 5 latent factors which are also known as user preferences and product properties. The weights for these factors are learnt by considering the reviews in addition to global average ratings and biases.

Reverse ASIN Lookup
Results
We compared our HFT model against 5 baseline methods. Each of the respective baseline method used has been explained in detail in the [[Methodology]] section.
Evaluation Metric
Our metrics for evaluation are Root Mean Squared Error (RMSE) and Mean Absolute Error (MAE), the formula for which are given below:
RMSE:
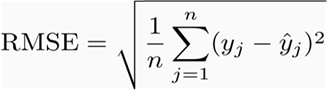
MAE:
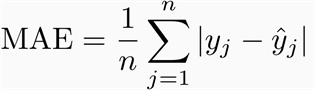
Findings
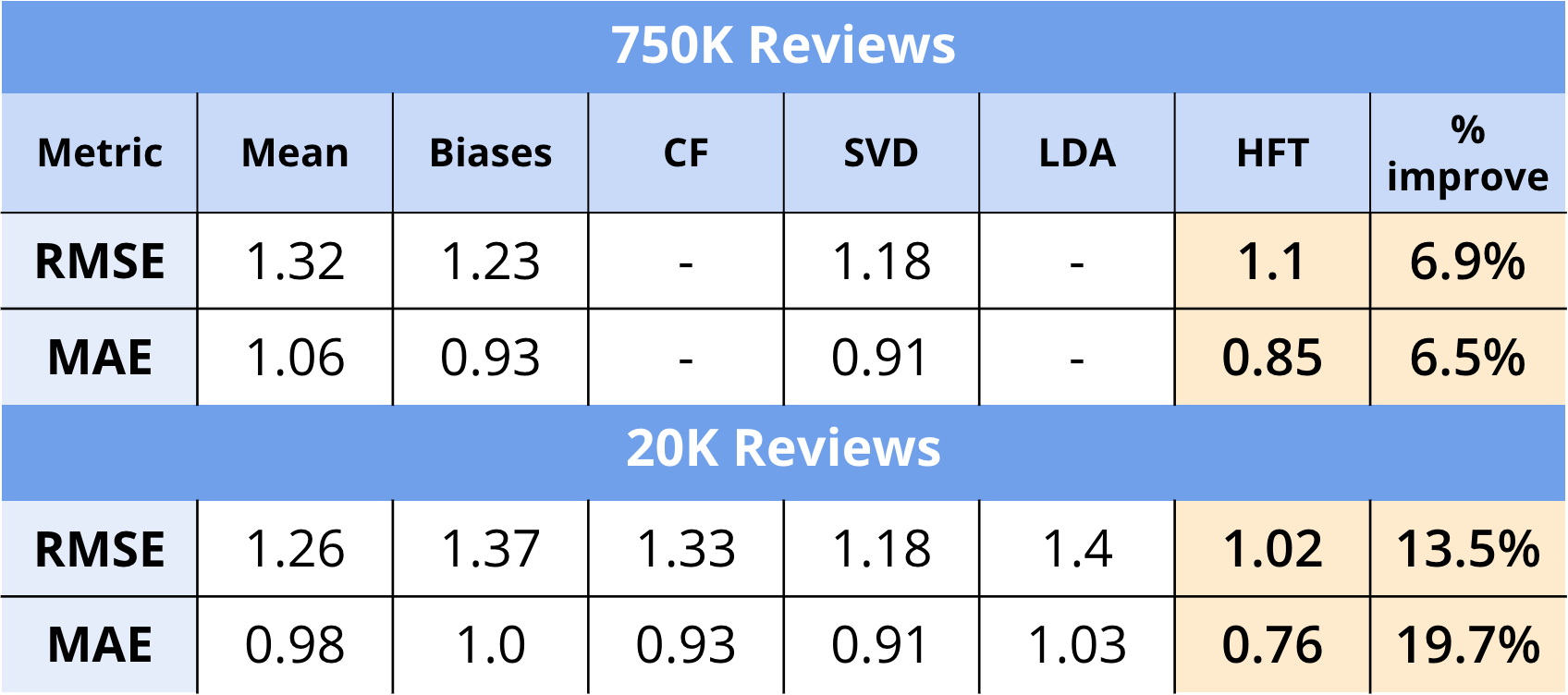
- In line with our original hypothesis, we can see that using the review text in combination with the numerical ratings hailed better results in terms of both RMSE and MAE.
- The HFT model performed the best with an RMSE of 1.1 on the whole 750K reviews, and an RMSE of 1.02 on 20K reviews.
- In the case of both datasets (750K, 20K) we saw a visible improvement in RMSE/MAE scores.
- We did not run the Collaborative Filtering model or Latent Dirichlet Allocation model on the 750K dataset due to lack of processing power and the sheer time taken to run these models.
- Additionally, it is interesting to note that most of our baseline methods (using only ratings) performed either better or roughly the same on the larger dataset, whereas the HFT model performed slightly worse.
Discussion
Challenges
- Creating a test set such that all items & users are in the train set too.
- Creating an automated Amazon ASIN lookup tool which is usually a paid service
- LDA Topics are not well defined for the dataset we chose.
- No ground truth for the predictions by using review texts only.
Takeaways
- Baseline approach is a good approach to start with, as it gives good recommendations in short time.
- In case of HFT, beyond a certain value, increasing the number of topics gives negligible improvements in RMSE.
- Using review topics in conjunction with ratings gives out better recommendations than traditional methods.
- It is difficult to make accurate predictions by relying solely on review text and biases (LDA).
- HFT is dataset dependent - some categories of items have reviews that better express the subjective tastes of the user/properties of the item
- App reviews are short and to-the-point, and mostly positive.
Future Work
- Word2Vec or GloVe can be used as part of hidden topic extraction from reviews
- The HFT model may be adapted to work with implicit data instead of ratings, along with just reviews.
Ethical Considerations
- Recommending violent/inappropriate apps to children?
- User profiles used for personalized recommendation may be used for malicious purposes
- Profile injection is also a possible attack to push or nuke items.
Technologies Used
Being a Graduate Course in Computer Science and Engineering (CSE) at Texas A&M University, the CSCE 670 - Information Storage and Retrieval course would obviously require us to write code as a part of the submission.
We outline below at a high level what programming languages we used, as well as which libraries and what purpose they were used for.
Programming Languages
Python
- Implementation of Baseline Approaches
- Scripts to split datasets into Train/test based on our customized requirements
- Scripts to scrape Amazon website to reverse lookup product details from an ASIN (Amazon Standard Identification Number) code
- Data Analysis and Exploration of our datasets
- Code to convert .json files to .votes files as required by HFT
C++
- Running of HFT models with custom modifications
Libraries/Packages
| Library Name | Usage |
|---|---|
| Pandas | Reading and writing data in ‘dataframes’ in Python |
| SkLearn, Scipy, Numpy | Matrix operations, calculation of RMSE, MAE, Pearson correlation, etc |
| Surprise | Implementation of SVD Approach |
| Matplotlib | Plotting data for analysis |
| Requests | Hitting URLs for Asin lookup |
| BeautifulSoup | HTML Parsing |
| pyLDAvis | Visualization of LDA topics |
Poster
References
[1] Julian McAuley and Jure Leskovec. 2013. Hidden factors and hidden topics: understanding rating dimensions
with review text. In Proceedings of the 7th ACM conference on Recommender systems (RecSys ‘13). ACM, New
York, NY, USA, 165-172. DOI=http://dx.doi.org/10.1145/2507157.2507163
[2] Yu, Kuifei, et al. “Towards personalized context-aware recommendation by mining context logs through topic models.” Pacific-Asia Conference on Knowledge Discovery and Data Mining. Springer, Berlin, Heidelberg, 2012.
[3] Yehuda Koren, Robert Bell, and Chris Volinsky. Matrix factorization techniques for recommender systems. 2009.
[4] Yehuda Koren. Factor in the neighbors: scalable and accurate collaborative filtering. 2010. URL: http://courses.ischool.berkeley.edu/i290-dm/s11/SECURE/a1-koren.pdf.
[5] Breese, John S., David Heckerman, and Carl Kadie. “Empirical analysis of predictive algorithms for collaborative filtering.” Proceedings of the Fourteenth conference on Uncertainty in artificial intelligence. Morgan Kaufmann Publishers Inc., 1998. URL: https://dl.acm.org/citation.cfm?id=2074100